Network source of truth — intent & inventory
Declare your network. Mean it.
IntentCenter is an API-first platform for authoritative network and facility inventory, safe automation, and closed-loop operations—built for provider-scale teams that need throughput, resilience, and operational maturity.
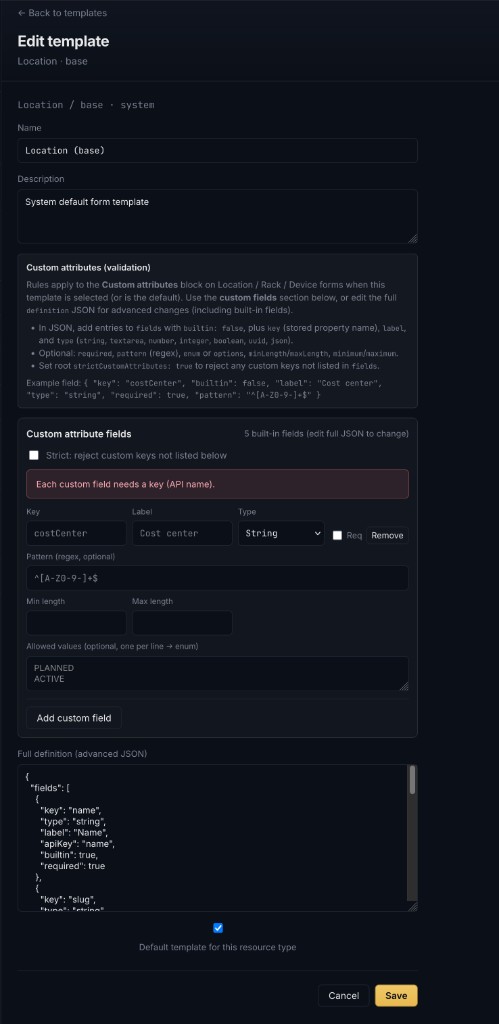
Forms stay aligned with the API through exported OpenAPI constraints; object templates let admins define custom attribute validation (regex, allowed values, strict key policies) without maintaining a parallel rule set in the UI.
About
What this project is
IntentCenter is an open, API-first platform for authoritative network and facility inventory—DCIM, IPAM, circuits, and relationships—plus safe automation, policy, and extensibility (plugins, connectors, operator-grade UX) so teams can run at real scale without giving up auditability, RBAC, or a clear system of record.
Why it exists
Large network and infrastructure orgs still feel a familiar gap: intent is scattered across tickets, spreadsheets, and tribal knowledge, while the inventory story is fragmented. That makes change riskier, automation harder to trust, and triage slower than it should be. We started IntentCenter to build a home where declared intent and grounded inventory meet—exposed through APIs and a console that NOC, field, and platform engineers can work in every day.
How we’re building it
The work sits on clean-room research and a greenfield implementation path: we synthesize design lessons from reference material (see the clean-room ↗ index in the repo) without copying third-party source, and we ship the product under the GNU AGPL-3.0 so you can run, study, and extend the platform on your own terms. The documentation hub and README ↗ carry the full vision, architecture, and roadmap.
Product
The operator console
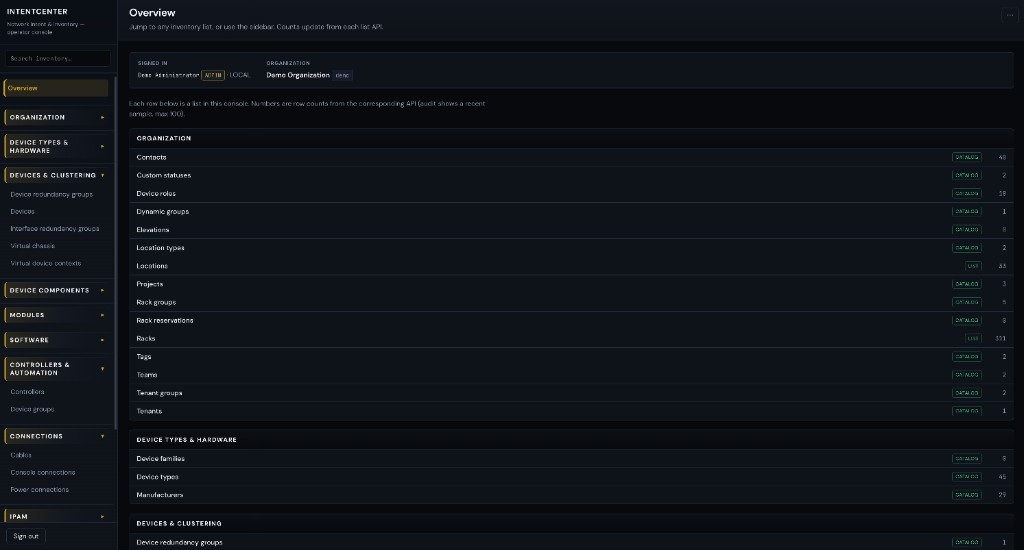
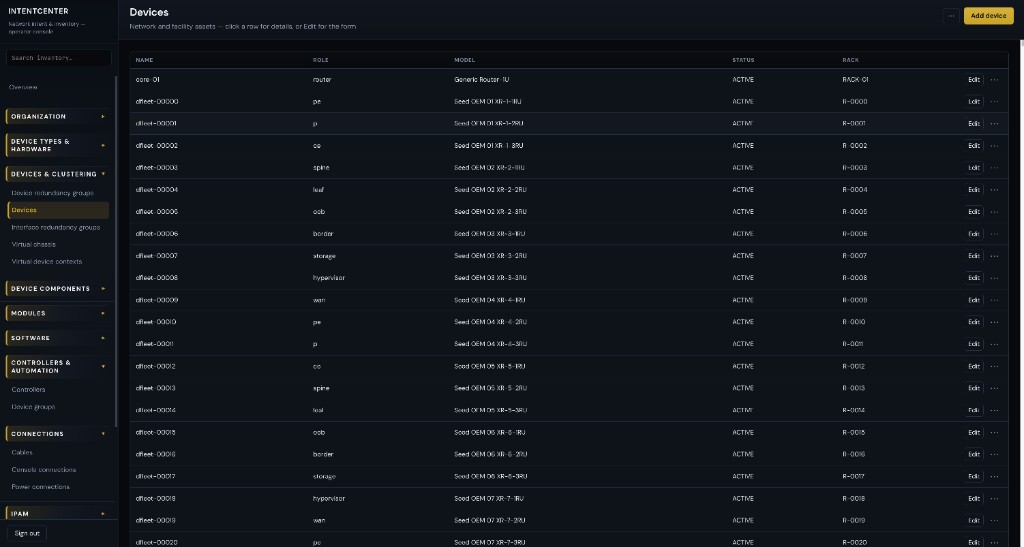
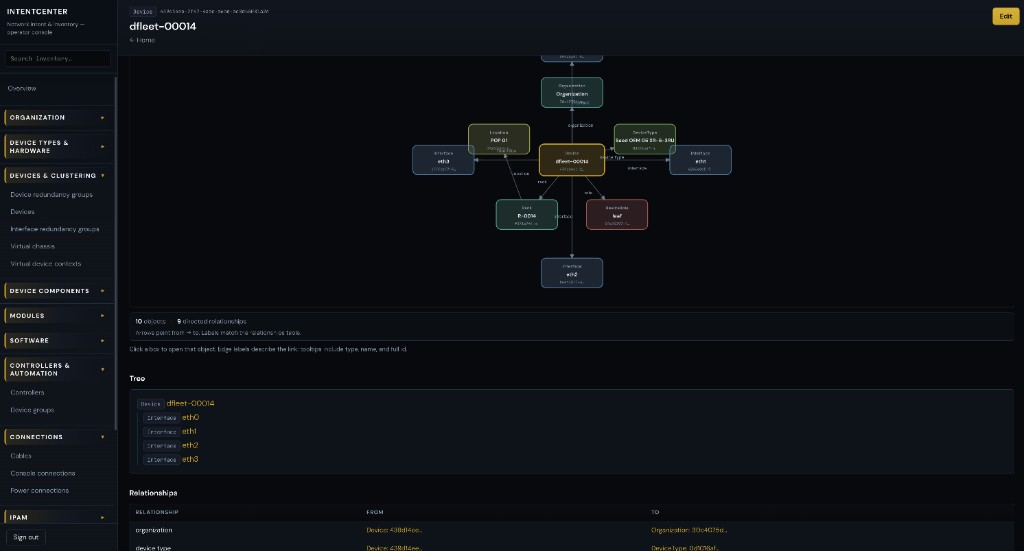
Platform
Four pillars
Source of truth
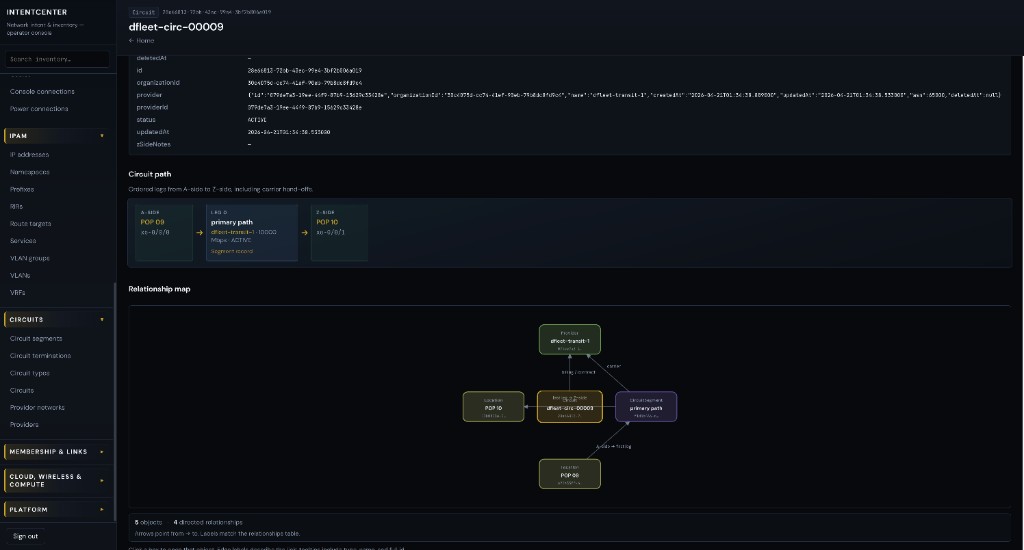
DCIM, IPAM, circuits, and relationships in one model—with versioned REST, GraphQL read paths, events, and bulk interchange—not scattered spreadsheets. Optional key/value custom attributes follow rules you declare per object template (same schema on the server and in the console).
Intent & automation
Orchestrate change through policies, approvals, and jobs; integrate with CI/CD, orchestrators, and northbound systems without giving up auditability.
Open & extensible
Org-scoped plugins & placements (widget slots on object views), connectors for controlled outbound calls, optional async job worker, and merged admin navigation from manifests—without forking core. Remote module install and federated iframes remain on the roadmap.
Operator-grade
Built for NOC, field, and platform engineers: global search, object graphs, bulk import/export, an in-app AI copilot grounded in tools, and runbooks-first operations.
Assistant
Intent Center AI
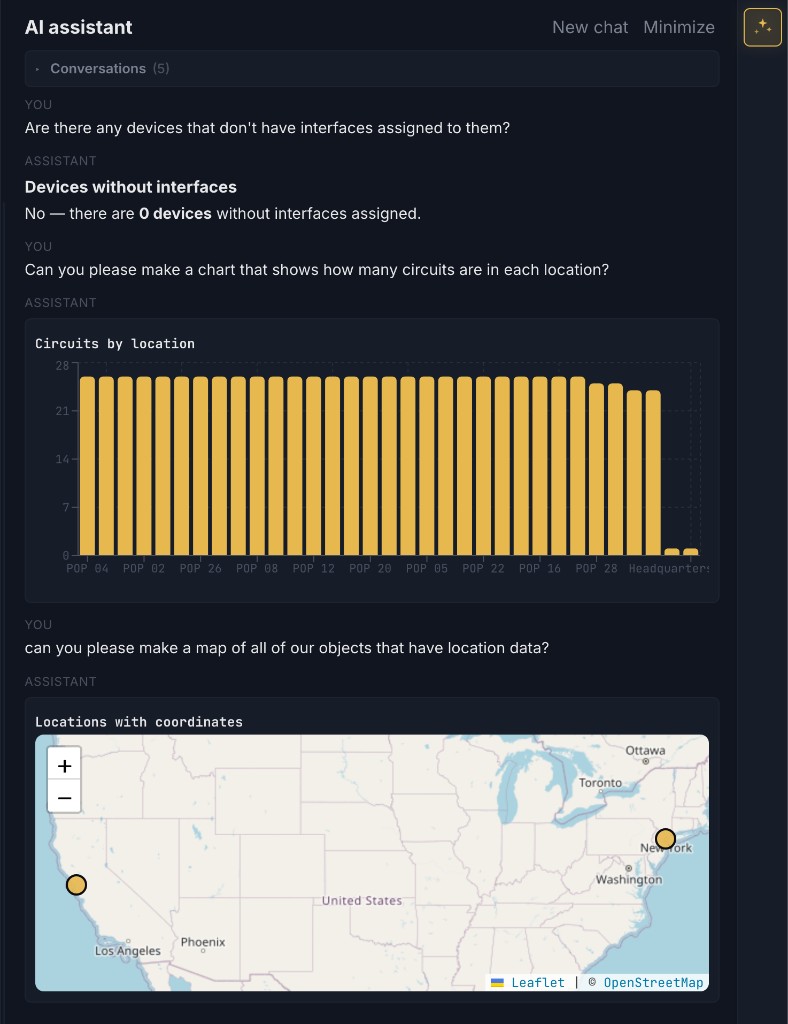
The console includes a built-in copilot that answers from your inventory using
server-side tools (search, object view and relationship graph, org-wide stats, composable
breakdowns and row lists, and change preview flows for safe proposals). Responses can include
data visualizations—for example, bar charts from catalog_breakdown and
maps from list_location_hierarchy when coordinates exist. Suggested
Next steps are tailored to the current page and chat, not only high-level
“org inventory” ideas. ADMIN can configure the OpenAI-compatible LLM in-app or
through environment variables; the API can optionally expose a Model Context Protocol
(MCP) endpoint at /mcp for external clients such as IDE assistants, using the same
API token model as the REST API.
For behavior, safety, and the optional MCP design, see the LLM assistant ↗ and MCP server ↗ in the repository.
For shared API/console validation, referential checks, and object-template custom attributes, see design-validation.md ↗.
Wishlist: deferred work and opportunities (SSO, plugin install, copilot/RAG depth, MCP policy, and more) are summarized on Wishlist & future work and checked off in the README ↗.
Operations
Sign-in & control plane
The operator console supports local email/password (optional) and configuration for
LDAP, Microsoft Entra ID, or OpenID Connect—at most one external
directory—through the admin Sign-in & identity page and AUTH_* environment
variables. API tokens and the audit log cover automation and compliance-style review.
See the docs hub and repository design notes for the full contract.